
Train an LLM on your DB schema

One of the most suitable use cases for LLMs is text-to-SQL, even though this is the case it takes a lot of effort to get an LLM to give right answers to your data questions.
Why is it not straight forward?
First of all, it's important to realize that these models are typically trained using substantial volumes of general SQL and text data. Although this extensive training greatly aids in their ability to comprehend plain language, it does not always prepare them to write precise SQL queries.
Understanding the exact database schema, table relationships, and data types is necessary for efficient text-to-SQL translation. Without further instruction or refinement, general-purpose LLMs may not be conversant with these details.
Complex questions requiring joins, subqueries, aggregations, and conditional logic can be more difficult for LLMs to handle, even though they may handle simple searches rather effectively.
Questions in natural language can be unclear. For instance, in order to answer the query "Show me the sales for last year," one must be aware of the precise meanings of the terms "sales" and "last year" in relation to the database.
So, How do we get the right results?
There are two methods to enhance an LLM to make it perform better: the first is to enhance context, and the second is to enhance behavior, or fine-tune.
These models have a good use case for fine tuning because they have already been trained on a vast amount of general SQL query sets. However, they also need to be improved in context. To achieve results that are more accurate than 83%+, a hybrid approach that incorporates context improvisation and fine tuning is required.
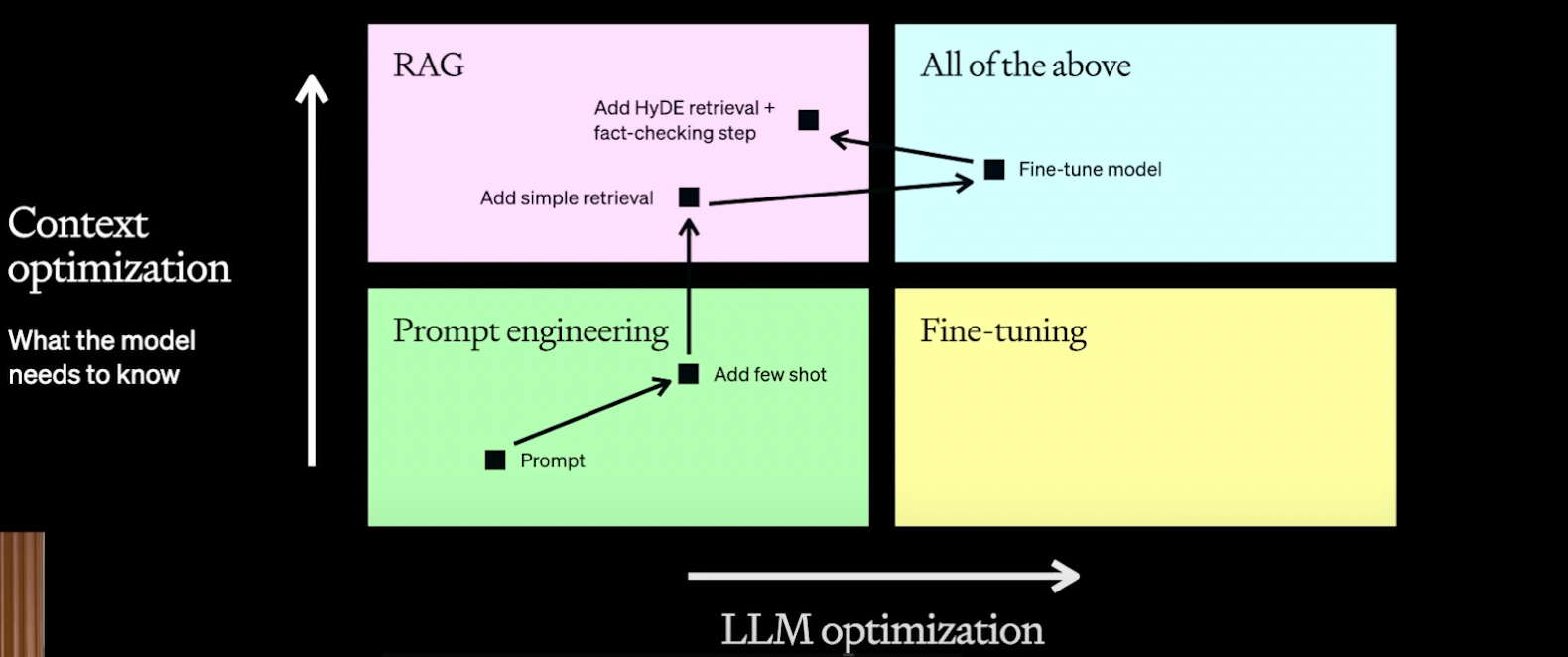
The above diagram shows how to approach this problem.
1. Start with simple prompting (By giving schema)
2. Add few examples to the prompt
3. Improve the context by adding relevant examples from RAG
4. Fine tune the model with example sets
5. Iteratively refining both the context and behaviour
Evaluation
Evaluation is one of the key factor when you are dealing with optimising an LLM, we need to make sure we are repeatedly evaluating the model performance at each level, this makes the model to improve periodically in the right direction.

In summary, there is promise but also difficulty when utilizing Large Language Models (LLMs) for text-to-SQL translation. It works well to use a hybrid method that combines model fine-tuning and context improvement. Accuracy can be greatly increased by the use of relevant examples, straightforward schema prompts, and iterative refining. Our approach has shown accuracy rates higher than 83%, indicating its usefulness.
By offering a platform that makes it simple for developers to create text-to-SQL models and implement analytical dashboards, we at EnqDB(visit) streamline this process and guarantee a smooth transition from model training to deployment.
Here is where you can attempt to develop your text to SQL model (Beta)
Ref -
https://www.youtube.com/watch?v=ahnGLM-RC1Y
https://platform.openai.com/docs/guides/fine-tuning